To create a smarter, more connected, and patient-centered future, explore our open platform that enhances data accessibility and supports informed decision-making for healthcare researchers, clinicians, and patients.
Modular Platform Overview
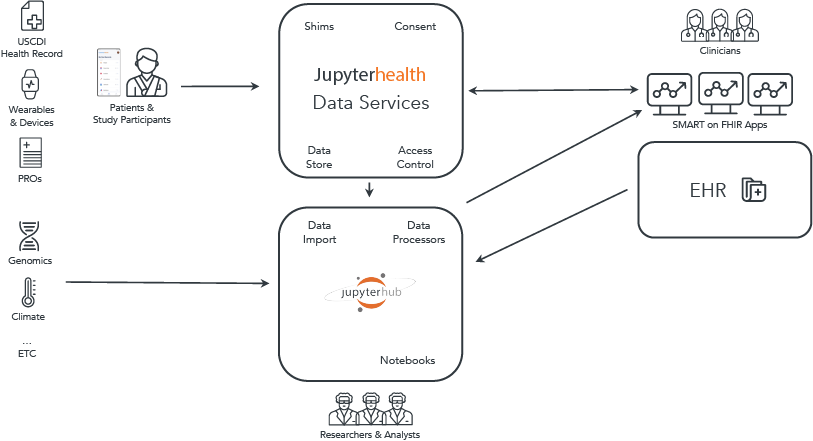
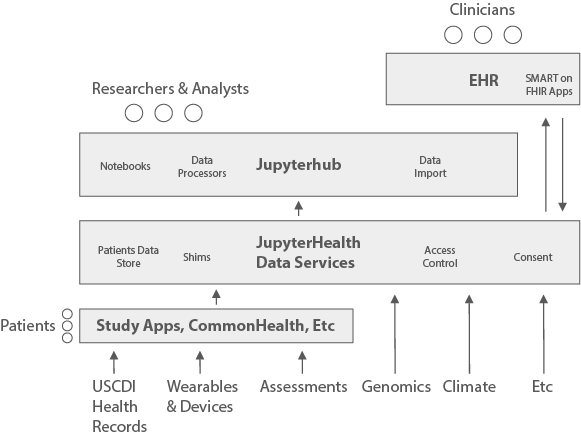
Empowering Healthcare with Modular Platform: JupyterHealth introduces a modular platform composed of open-source components that span the entire lifecycle of digital health research, development, and deployment. From data ingestion involving wearable and clinical data to advanced data analysis and presentation via JupyterHub and Voila, each component is designed to operate independently or in conjunction. This modular setup not only supports rigorous health data standards like HL7 FHIR and Open mHealth but also offers customizable environments to suit diverse operational needs – from secure data storage and robust authentication systems to real-time data processing and scalable infrastructure.
Why Choose JupyterHealth?
Democratizing Health Data Management: Historically, the integration of real-world data from patients into research and clinical care has been confined to the largest and most technologically sophisticated organizations. JupyterHealth is changing this landscape by championing open-source platforms and accessibility for all. Our initiatives are designed to level the playing field, allowing varied healthcare entities and research organizations to leverage comprehensive data for improved care and research outcomes.
Empowering Research and Care with Open Source Technology: JupyterHealth embodies the ethos of Project Jupyter, bringing open-source software, shareable notebooks, and reproducible code into the healthcare domain. Our vendor-agnostic infrastructure ensures that various research groups and healthcare providers can adopt and adapt our platform without barriers, fostering unprecedented levels of collaboration across the healthcare ecosystem.
Ensuring Interoperability and Data Sovereignty: In partnership with The Commons Project (TCP), we focus on ensuring that our technical stack is interoperable with standard U.S. healthcare protocols. This collaboration not only expands our platform’s capabilities but also allows various organizations to develop and implement advanced health technologies. JupyterHealth facilitates seamless data sharing among Common Health users and healthcare providers, enhancing data sovereignty and empowering users to fully control their data and infrastructure.
Streamlining Interactive Computing for Healthcare Professionals: In partnership with Project Jupyter and International Interactive Computing Collaboration (2i2c), we advance interactive computing to support healthcare research and clinical practice. JupyterHub centralizes access to computational tools, removing the burden of software management and allowing healthcare professionals to concentrate on patient outcomes rather than IT overhead. Our platform is scalable and customizable, ensuring it meets the diverse needs of the healthcare community.
JupyterHealth Modular Platform
JupyterHealth will be a modular platform consisting of open-source components that span the life cycle of digital health research, development, and deployment. Our approach ensures that each module can function independently or in conjunction, providing flexibility and scalability to meet diverse healthcare needs. Below is a detailed overview of each module:
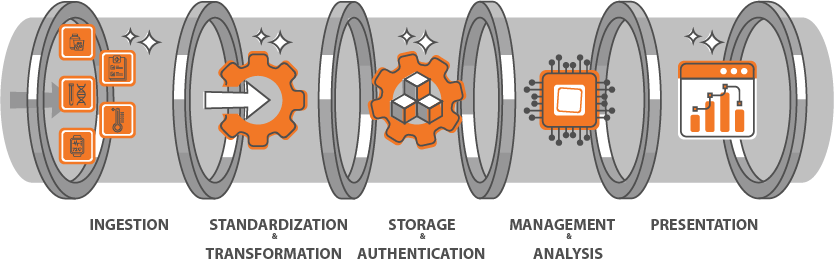
- Data Ingestion: Seamlessly integrate data from wearable devices, electronic health records (EHRs), and other key health data sources, ensuring a steady flow into JupyterHealth environment. More specifically this will include at least the following:
- Tools to acquire wearable and clinical data from Apple HealthKit and CommonHealth
- Shims to acquire wearable data from the most common manufacturers
- Interfaces to import clinical data from federally certified EHR platforms
- Data Standardization and Transformation: Utilizing tools to standardize and filter data from disparate health data sources, making it easier to work with and analyze. More specifically this will include at least the following:
- Tools to standardize wearable data to Open mHealth and FHIR formats
- Templates for other transformations.
- Storage and Authentication: Securely store and manage access to sensitive health data including PHI. More specifically this will include at least the following:
- Reference SMART on FHIR server capable of storing data as FHIR, Open mHealth, and other formats, and managing authentication and access.
- Modules for connecting to common databases and data lakes
- Modules to connect existing authentication services, eg via OIDC.
- Data Management and Analysis: Leverage JupyterHub for working with and combining data sets, data exploration, analysis, and algorithm development. JupyterHub (documentation) provides the core environment for managing and conducting data analyses. JupyterHub can be used for health-related data work today so long as care is taken with protected data. Additional components will include at least:
- JupyterHub modules for incorporating data from health data storage
- Health data-specific analysis packages and libraries contributed by the community.
- Presentation: Not only to share research and analysis findings but to give care providers data views and visualizations that fit with their current patient workflows. Jupyter Voila (documentation) is a starting point for visualizing Notebooks and outputs of developed algorithms. Beyond existing tools, this will include at least:
- Modules for deploying standardized SMART Launch applications to the major EHR platforms supporting federally mandated APIs.
Standard Compliance
JupyterHealth modules are being built on top of trusted open health data interoperability standards, most of which are federally mandated in the US:
- Clinical data will adhere to US Core and by extension could support International Patient Access outside the US.
- Wearable and patient-generated data will be Open mHealth and FHIR
- Authentication will follow SMART on FHIR
This detailed framework underlines our commitment to providing a robust, scalable, and secure environment for healthcare data management and analysis, empowering researchers, clinicians, and technologists to drive innovation in healthcare.